快速开始
算法实现与验证demo
代码详情参考 test_flux_double_anti.py
graph TD
A[初始化FluxTransformerBlock_anti] --> B[加载原始模型参数]
B --> C[生成Smooth Scale因子(固定种子)]
C --> D1[QKV投影层融合]
D1 --> D2[下调AdaLayerNorm参数]
D2 --> D3[上调QKV投影层权重]
C --> E1[MLP Up投影层融合]
E1 --> E2[下调MLP相关的AdaLayerNorm参数]
E2 --> E3[上调MLP Up投影层权重]
C --> F1[Att-O融合]
F1 --> F2[下调Value投影层参数]
F2 --> F3[上调注意力输出层权重]
D3 --> G[验证输出等价性]
E3 --> G
F3 --> G
G --> H{输出误差<阈值?}
H -->|是| I[测试通过]
H -->|否| J[测试失败]
style I fill:#9f9,stroke:#333,stroke-width:2px
style J fill:#f66,stroke:#333,stroke-width:2px
验证指标:
输出误差δy=imaxyi(orig)−yi(fused)
要求δy<10−5以保证数值等价性。
运行验证代码:
pip install git+https://github.com/hhqx/FLUX.1-dev.git
- [Optional] install from source
# git clone <This repo>
git clone git@github.com:hhqx/FLUX.1-dev.git
cd FLUX.1-dev
pip install -e .
# 运行验证代码
python -m tests.test_anti_smooth.test_flux_double_anti
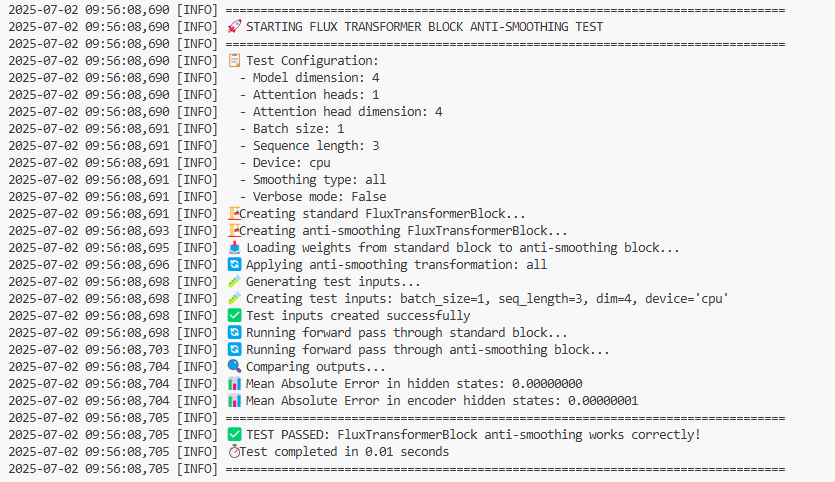
验证结果示例:
输出结果:
$ python -m tests.test_anti_smooth.test_flux_double_anti
第一章 绪论
1.1 研究背景
随着Transformer模型规模的不断扩大,模型量化成为降低计算资源需求的关键技术。然而,传统量化方法在非线性操作密集的Transformer架构中面临显著精度损失。SmoothQuant通过参数重校准技术,在维持计算等价性的前提下提升模型量化友好性,其核心在于尺度因子融合策略的创新设计。
graph LR
subgraph "原始计算路径"
A1[归一化层] --> B1[特征输出]
B1 --> C1[线性投影层]
C1 --> D1[输出]
end
subgraph "应用SmoothQuant后"
A2[归一化层÷S] --> B2[缩小的特征输出]
B2 --> C2[S×线性投影层]
C2 --> D2[等价输出]
end
style D1 fill:#f9f,stroke:#333,stroke-width:2px
style D2 fill:#f9f,stroke:#333,stroke-width:2px
style B2 fill:#bbf,stroke:#333,stroke-width:1px
style C2 fill:#bbf,stroke:#333,stroke-width:1px
1.2 研究内容
本章聚焦SmoothQuant在Transformer量化中的尺度融合机制,通过数学建模严格推导其在四类关键组件(QKV投影-归一化层、MLP上行投影-归一化层、MLP下行投影-上行投影层、注意力输出层-Value投影层)的等价性与非等价性条件,为高效量化提供理论基础。
第二章 SmoothQuant尺度融合在多模态AdaNorm中的设计与实现
2.1 QKV投影与AdaLayerNorm融合的等价性方案
建模过程:
设输入x∈Rd,AdaLayerNormZero输出:
h=归一化norm(x)⊙自适应缩放(1+gmsa)+自适应平移smsa
graph TD
subgraph "AdaLayerNormZero Forward Computation"
Emb[嵌入向量] --> SiLU[SiLU激活]
SiLU --> Linear[线性变换]
Linear --> Chunk["分块操作"]
Chunk --> |shift_msa| ShiftPath["+"]
Chunk --> |scale_msa| ScalePath["×"]
Input[输入 x] --> Norm["norm(x)"]
Norm --> ScalePath
ScalePath --> |"X*(1+scale_msa)"| ShiftPath["add"]
ShiftPath --> |"X*(1+scale_msa)+shift_msa"| Output["输出"]
end
QKV投影输出:
y=hWqkv,Wqkv∈Rd×3d
尺度融合变换:
- 生成尺度因子:
σ=2+∣N(0,I)∣∈Rd
(确定性生成)
- 归一化层参数降尺度:
Wnorm,shift′bnorm,shift′Wnorm,scale′bnorm,scale′=Wnorm,shift⋅diag(σ)−1=bnorm,shift⋅diag(σ)−1=Wnorm,scale⋅diag(σ)−1=(bnorm,scale+1)⋅diag(σ)−1−1
- QKV投影升尺度:
Wqkv′=diag(σ)⋅Wqkv
graph TD
subgraph "QKV AdaNorm 异常值抑制"
Ada["AdaLayerNormZero"] --> QKV["QKV Projection"]
QKV --> Out["Output"]
Smooth["Generate scale"] --> ScaleDown["AdaLayerNorm Parameter Downscaling"]
Smooth --> ScaleUp["QKV Weight Upscaling"]
ScaleDown -.-> |"W_norm · diag(σ)^-1"| Ada
ScaleUp -.-> |"diag(σ) · W_qkv"| QKV
end
style ScaleDown fill:#bbf,stroke:#333,stroke-width:1px
style ScaleUp fill:#bbf,stroke:#333,stroke-width:1px
此时:
(1+gmsa′)=(1+gmsa)diag(σ)−1
smsa′=smsa⋅diag(σ)−1
等价性证明:
原始输出:
y=hWqkv=[norm(x)⊙(1+gmsa)+smsa]Wqkv
融合后输出:
y′=[norm(x)⊙(1+gmsa′)+smsa′]Wqkv′=[norm(x)⊙((1+gmsa)diag(σ)−1)+smsadiag(σ)−1](diag(σ)Wqkv)=(h⋅diag(σ)−1)(diag(σ)Wqkv)=h⋅Idiag(σ)−1diag(σ)⋅Wqkv=y
故
y′≡y
,计算等价性得证。
graph LR
x["输入 x"] --> Norm["norm(x)"]
Norm --> M1["× (1 + scale_msa)"]
M1 --> Add1["Add"]
shift["shift_msa"] --> Add1
Add1 --> M2["@ W_qkv"]
M2 --> Out1["原始输出"]
x2["输入 x"] --> Norm2["norm(x)"]
Norm2 --> M3["× (1 + scale_msa)/S"]
M3 --> Add2["Add"]
shift2["shift_msa/S"] --> Add2
Add2 --> M4["@ (W_qkv·S)"]
M4 --> Out2["融合后输出"]
Out1 --> Equal["="]
Out2 --> Equal
style Equal fill:#9f9,stroke:#333,stroke-width:4px
style M3 fill:#bbf,stroke:#333,stroke-width:1px
style M4 fill:#bbf,stroke:#333,stroke-width:1px
2.2 MLP up投影层与AdaLayerNorm融合的等价性方案
建模过程:
设输入向量为 x∈R1×din,上行投影权重矩阵为 Wup∈Rdin×dhid,偏置向量为 bup∈R1×dhid。
上行投影输出为:
u=xWup+bup
其中 u∈R1×dhid。
graph LR
subgraph "原始MLP路径"
AdaNorm1[AdaLayerNorm] --> |scale_mlp, shift_mlp| Norm1[归一化输出]
Norm1 --> MLPUp1[MLP Up投影]
MLPUp1 --> Out1[特征输出]
end
subgraph "融合后MLP路径"
AdaNorm2[AdaLayerNorm] --> |scale_mlp÷S, shift_mlp÷S| Norm2[缩小的归一化输出]
Norm2 --> MLPUp2[MLP Up投影×S]
MLPUp2 --> Out2[等价特征输出]
end
style Out1 fill:#f96,stroke:#333,stroke-width:2px
style Out2 fill:#f96,stroke:#333,stroke-width:2px
style Norm2 fill:#bbf,stroke:#333,stroke-width:1px
style MLPUp2 fill:#bbf,stroke:#333,stroke-width:1px
尺度融合变换:
定义对角尺度矩阵 S=diag(σ)∈Rdhid×dhid,其中 σ=(σ1,σ2,…,σdhid)⊤>0。
MLP上行投影参数变换:
Wup′=diag(σ)⋅Wup,smlp′=smlp⋅diag(σ)−1,1+gmlp′=(1+gmlp)⋅diag(σ)−1
融合后计算过程:
z′=[norm(x)⊙(1+gmlp′)+smlp′]@Wup′=[norm(x)⊙((1+gmlp)⋅diag(σ)−1)+smlp⋅diag(σ)−1]@(diag(σ)⋅Wup)=[(norm(x)⊙(1+gmlp)+smlp)⋅diag(σ)−1]@(diag(σ)⋅Wup)=(h⋅diag(σ)−1)@(diag(σ)⋅Wup)=h@(diag(σ)−1⋅diag(σ))@Wup=h@I@Wup=h@Wup=z
2.3 MLP下行投影融合的非等价性
建模过程:
设输入向量为 x∈R1×din,上行投影权重矩阵为 Wup∈Rdin×dhid,偏置向量为 bup∈R1×dhid。
上行投影输出为:
u=xWup+bup
其中 u∈R1×dhid。
激活函数 f:R→R 逐元素作用于向量:
v=f(u)=[f(u1)f(u2)⋯f(udhid)]
下行投影权重矩阵为 Wdown∈Rdhid×dout,最终输出:
y=vWdown
graph LR
subgraph "原始前向路径"
x1[输入] --> MLPUp1[MLP Up投影]
MLPUp1 --> |线性输出| Act1["激活函数f()"]
Act1 --> |非线性输出| MLPDown1[MLP Down投影]
MLPDown1 --> Out1[输出]
end
subgraph "融合后路径(非等价)"
x2[输入] --> MLPUp2["MLP Up投影÷S"]
MLPUp2 --> |缩小的线性输出| Act2["激活函数f()"]
Act2 --> |非线性修改后的输出| MLPDown2["S × MLP Down投影"]
MLPDown2 --> Out2[不等价输出]
NonEq["f(x/S) ≠ f(x)/S"]
end
style Out1 fill:#f96,stroke:#333,stroke-width:2px
style Out2 fill:#f66,stroke:#333,stroke-width:2px,stroke-dasharray: 5 5
style NonEq fill:#f66,stroke:#333,stroke-width:2px
尺度融合变换:
定义对角尺度矩阵 S=diag(σ)∈Rdhid×dhid,其中 σ=(σ1,σ2,…,σdhid)⊤>0。
-
上行投影参数变换:
Wup′=WupS−1,bup′=bupS−1
变换后上行投影输出:
u′=xWup′+bup′=(xWup+bup)S−1=uS−1
-
下行投影参数变换:
Wdown′=SWdown
非等价性分析:
融合后输出:
y′=f(u′)Wdown′=f(uS−1)(SWdown)
原始输出:
y=f(u)Wdown
等价性条件:
要使 y′=y,需满足:
f(uS−1)S=f(u)
即对每个分量 j:
f(σjuj)σj=f(uj)
对于非线性函数(如GELU或SiLU),这一等式不成立,即:
activation(u⋅diag(σ)−1)=activation(u)⋅diag(σ)−1
2.4 注意力输出层融合的等价性方案
建模过程:
Value投影输出:
V=XWv+bv
注意力权重:
A=softmax(dQK⊤)
输出投影:
y=(AV)Wo
graph TD
subgraph "原始注意力计算"
x1[输入] --> V1["Value投影 (x @ W_v + b_v)"]
QK1["Q·K^T/√d"] --> Soft1["Softmax"]
Soft1 --> Dot1["矩阵乘法"]
V1 --> Dot1
Dot1 --> AttO1["注意力输出投影"]
AttO1 --> Out1[输出]
end
subgraph "融合后注意力计算"
x2[输入] --> V2["Value投影 (x @ W_v/S + b_v/S)"]
QK2["Q·K^T/√d"] --> Soft2["Softmax"]
Soft2 --> Dot2["矩阵乘法"]
V2 --> Dot2
Dot2 --> AttO2["S × 注意力输出投影"]
AttO2 --> Out2[等价输出]
end
style Out1 fill:#f96,stroke:#333,stroke-width:2px
style Out2 fill:#f96,stroke:#333,stroke-width:2px
style V2 fill:#bbf,stroke:#333,stroke-width:1px
style AttO2 fill:#bbf,stroke:#333,stroke-width:1px
尺度融合变换:
- Value投影降尺度:
Wv′=Wvdiag(σ)−1,bv′=bv⋅diag(σ)−1
- 输出投影升尺度:
Wo′=diag(σ)Wo
等价性证明:
融合后计算路径:
V′O′y′=Vdiag(σ)−1=AV′=AVdiag(σ)−1=Odiag(σ)−1=O′Wo′=(Odiag(σ)−1)(diag(σWo))=OIdiag(σ)−1diag(σ)Wo=y
线性矩阵乘法保持运算等价性。
graph TD
subgraph "融合前注意力计算"
V1["V = x @ W_v + b_v"] --> Att1["Attention计算"]
Att1 --> O1["O = Softmax(QK^T/√d)·V"]
O1 --> OutProj1["output = O @ W_o"]
end
subgraph "融合后注意力输出计算"
V2["V' = x @ (W_v/S) + b_v/S = V/S"] --> Att2["Attention计算"]
Att2 --> O2["O' = Softmax(QK^T/√d)·V' = O/S"]
O2 --> OutProj2["output' = O' @ (W_o·S) = O @ W_o"]
end
OutProj1 --> Equal["="]
OutProj2 --> Equal
style Equal fill:#9f9,stroke:#333,stroke-width:4px
style V2 fill:#bbf,stroke:#333,stroke-width:1px
style O2 fill:#bbf,stroke:#333,stroke-width:1px
style OutProj2 fill:#bbf,stroke:#333,stroke-width:1px
第四章 结论与讨论
-
理论贡献:
- 严格证明SmoothQuant在线性投影-归一化层组合中的计算等价性
- 揭示非线性激活函数是破坏MLP下行投影等价性的根本原因
- 建立注意力机制中跨层尺度融合的可行性条件
-
工程指导:
| 组件类型 |
可融合性 |
关键约束 |
| QKV投影+归一化 |
✓ |
尺度因子同步更新 |
| MLP上行+归一化 |
✓ |
偏置项特殊处理 |
| MLP下行+上行 |
✗ |
非线性激活不可逆 |
| 注意力输出+Value |
✓ |
矩阵乘法线性性 |
AdaNorm 融合前后权重参数对照表
| 参数 |
原始值 |
融合后值 |
维度 |
代码实现 |
| Wnorm,shift |
W |
σW |
(∗,D) |
norm1.linear.weight.data[:dim].div_(scale.view(-1, 1)) |
| bnorm,shift |
b |
σb |
(D,) |
norm1.linear.bias.data[:dim].div_(scale) |
| Wnorm,scale |
W |
σW |
(∗,D) |
norm1.linear.weight.data[dim:2*dim].div_(scale.view(-1, 1)) |
| bnorm,scale |
b |
σb+1−1 |
(D,) |
norm1.linear.bias.data[dim:2*dim] = (bias_slice + 1) / scale - 1 |
| Wqkv |
W |
σ⊗W |
(D,∗) |
linear.weight.data.mul_(scale.view(1, -1)) |
表示约定说明:
-
数学表示(列优先存储):
- 线性层运算:Y=XWnorm,scale+b
- 权重维度:Wnorm,scale∈R∗×D
-
代码实现(行优先存储):
- 线性层运算:Y=XWnorm,scale⊤+b
- 权重维度:Wnorm,scale∈RD×∗
-
操作符说明:
- D:表示异常值抑制的维度,即AdaNorm的输出维度,与QKV投影层输入维度一致
- σ:尺度因子向量,通过 diag(σ) 构造对角矩阵
- ⊗:表示矩阵乘法 diag(σ)⋅W(维度适配广播)
- σ□:表示逐元素除以尺度因子
附录:数学符号表
| 符号 |
含义 |
维度 |
Wqkv
|
QKV投影权重 |
Rd×3d
|
gmsa
|
自注意力缩放因子 |
Rd
|
σ
|
尺度因子向量 |
Rd
|
diag(⋅)
|
对角矩阵化算子 |
- |
⊙
|
逐元素乘法 |
- |
f(⋅)
|
非线性激活函数 |
- |
安装与运行
安装方法
提供两种安装方式:
- 从源代码安装 (推荐用于开发)
git clone git@github.com:hhqx/FLUX.1-dev.git
cd FLUX.1-dev
pip install -e .
- 直接从GitHub安装 (适用于快速试用)
pip install git+https://github.com/hhqx/FLUX.1-dev.git
运行测试
执行验证测试脚本:
python -m tests.test_anti_smooth.test_flux_double_anti
python -m tests.test_anti_smooth.test_flux_double_anti --verbose
更多运行选项请参考:
python -m tests.test_anti_smooth.test_flux_double_anti --help